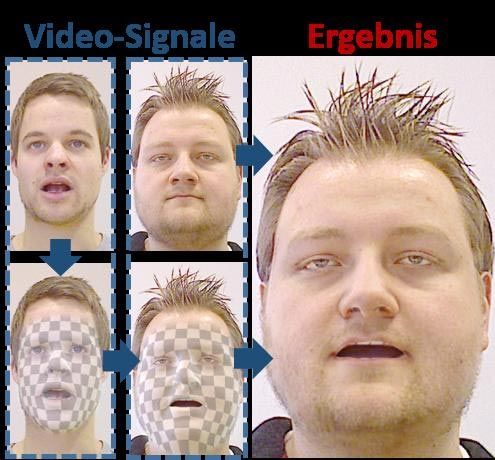
Die Technik erlaubt es, die Mimik einer Person auf das Gesicht einer anderen in Echtzeit zu übertragen.
Was einer Gruppe von Wissenschaftern aus den USA und Deutschland gelungen ist, klingt beeindruckend und erschreckend zugleich: Die Forscher schafften es, Mimik und Lippenbewegungen einer Person in Echtzeit auf das Video-Signal einer anderen Person zu übertragen. Die Gestik und Kopfbewegungen der Ursprungsperson bleiben dabei unverändert. Mit dieser Technik wäre es ohne weiteres möglich, einer Person während Liveberichten Worte buchstäblich in den Mund zu legen, die diese so nie gesagt hat. Nicht nur, dass das Resultat selbst auf den zweiten Blick überzeugend aussieht und keine Spur eine Manipulation zu erkennen ist, die dafür entwickelten Algorithmen sind auch noch so effizient, dass die Rechenleistung von Standard-Hardware für derartige Echtzeit-Videofälschungen ausreichend ist.
Für diese Methode werden beide Personen von einer Kamera gefilmt, die zusätzlich zu normalen Bildinformationen auch Tiefendaten aufnimmt. Solche Kameras vermessen also zusätzlich die Entfernung jedes Bildpunktes zur Szene. Basierend auf diesen Daten, werden in einem Vorverarbeitungsschritt, für beide Personen die Parameter eines Gesichtsmodells geschätzt, so dass Kopfgeometrie und Reflektanz in einer mathematischen Beschreibung vorliegen. Danach wird die Mimik und Lippenbewegung beider Personen analysiert und von einem Gesichtsmodell auf das andere übertragen, und im Zielvideo fotorealistisch dargestellt.
Verbesserungen bei Film-Synchronisation
Dank jahrelanger erfolgreicher Forschung sind die Algorithmen zur Berechnung mittlerweile so effizient, dass sie auf gut ausgestatteten Standardrechnern in Echtzeit ablaufen können. Dies ist durch eine geschickte Verlagerung der teils aufwändigen Rekonstruktionsschritte auf moderne Graphikhardware möglich. Mögliche Anwendungen sehen Justus Thies (Universität Erlangen-Nürnberg) und Michael Zollhöfer (Max-Planck-Institut für Informatik) in der visuellen Verbesserung von Nachvertonungen bzw. Synchronisationen, also wenn der Protagonist in einer Sprache spricht, aber der Zuschauer eine andere Sprache hört, wie z.B. bei fremdsprachigen Spielfilmen. Dazu werden die Lippenbewegungen mit der Synchronsprache abgeglichen.
Die Forscher arbeiten seit langem an Fragen der Grundlagenforschung im Bereich Bildverstehen, insbesondere an neuen Methoden um dynamische Szenenmodelle (Geometrie, Reflektanz von Objekten) aus Videos zu schätzen. "Insbesondere geht es darum, Modelle aus Videodaten von nur wenigen, oder gar nur einer Kamera zu berechnen, um eine mathematisch, möglichst realitätsgetreue Beschreibung von starren, beweglichen aber auch deformierbaren Körpern innerhalb einer Szene zu schätzen", erklärt Christian Theobalt am MPI für Informatik in Saarbrücken. Dies sei ein sehr schwieriges und rechenaufwändiges Problem, und die entwickelten Methoden seien auch anderweitig einsetzbar. "Grundsätzlich sind die Arbeiten als ein Baustein für Techniken zu verstehen, die es Computern ermöglichen die bewegte Welt um sich herum zu erfassen, und mit vielen Anwendungen in der Robotik oder Augmented/Virtual Reality zu interagieren", so Theobalt.
Die Arbeit zeigt aber auch, dass mittlerweile selbst die täuschend echte Manipulation von Live-Video-Streams in den Bereich des Möglichen kommt. So, wie jeder heute weiß, dass Bilder und Filme für Werbe- oder auch Propagandazwecke verfälscht werden können, müssen in Zukunft auch bei Live-Videos Manipulationsmöglichkeiten in Betracht gezogen werden. Offiziell wird das Verfahren im November auf der Computergraphik-Konferenz SIGGRAPH ASIA in Kobe (Japan) vorgestellt. (red, 1.11.2015)